DistractiveEnv#
- class curiosity_gym.envs.distractiveenv.DistractiveEnv(agentPOV: AgentPOV | str = 'global', render_mode: str | None = None, window_width: int = 1200)#
Defines the structure of the curiosity-gym distractive rewards environment.
It consists of two corridors. The left corridor contains small but frequent rewards, while the right corridor contains a larger but sparse reward. The environment is designed to test the agent’s capability of escaping local reward optima (represented by the left corridor) to find a global sparse optimum (represented by the right corridor). The maximum step count is set to 50, so that the agent can not obtain rewards from both corridors within one episode.
- Parameters:
agentPOV (
AgentPOV| str, optional) – Object or string defining the observations and action spaces of the RL agent. Valid string values are ‘global’, ‘local_W’ and ‘forward_L_W’, where W and L are integers defining the width and length of the respective POV. By defaultGlobalView.render_mode (str | None, optional) – Render mode in which the environment is run. If render mode is human, the environment will be rendered in PyGame. By default None.
window_width (int, optional) – Horizontal size of the PyGame window in human render mode. By default 1200.
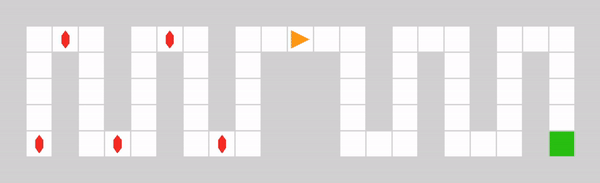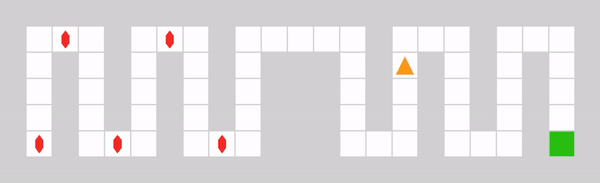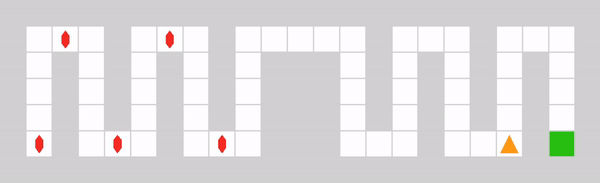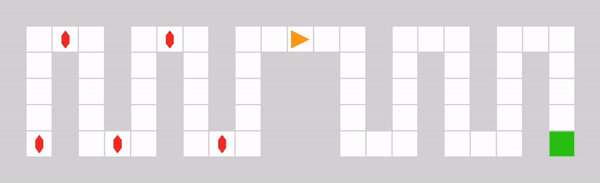
Example of a DistractiveEnv episode with an optimal policy.#
Methods
Check whether the agent has reached the target at the end of the right corridor.
Clean up the environment.
Get non-wall grid object at given position.
Get ids for all grid object types.
Get the current state of the environment.
Gets the attribute name from the environment.
Checks if the attribute name exists in the environment.
Display heatmap of position counts of the agent.
Initialise render objects.
Convert array of positions to wall objects for environment.
Compute the render frames as specified by
render_mode.Reset the environment to an initial internal state.
Sets the attribute name on the environment with value.
Simulate the state of the environment if a given action were taken.
Run one timestep of the environment’s dynamics using the agent actions.
Attributes
metadataMetadata of the environment.
np_randomReturns the environment's internal
_np_randomthat if not set will initialise with a random seed.np_random_seedReturns the environment's internal
_np_random_seedthat if not set will first initialise with a random int as seed.render_modeRender mode in which the environment is run.
specunwrappedReturns the base non-wrapped environment.
reward_rangeRange of rewards that can be obtained within one episode.
action_spaceSpace of possible actions a RL agent can choose from.
observation_spaceSpace of possible observations returned by the environment.